정리를 해야하는 이유
- 컴퓨터 성능, 신뢰성, 에너지 효율성 등을 결정하기 때문에 우리는 컴퓨터 구조에 대해 알아야 한다.
정리하며 알아야 할 것
- 컴퓨터 구조와 구성요소
- 구성요소들의 상호작용에 대한 설계
<자료구조>
스택
: LIFO(Last In First Out)
: 삽입삭제가 항상 제일 뒤(최근 요소에서 이루어진다.)
큐
: LIFO(Last In First Out)
: 리스트 큐, 원형 큐가 있다
Array
: 연속된 메모리 공간에 같은 타입의 데이터를 순차적으로 저장하는 자료구조
: 인덱스로 빠르게 접근 가능
: 크기가 고정되어있기 때문에 배열 생성시 크기를 지정해줘야함
LinkList
: Array와는 다르게 메모리를 할당하지 않아도 자유롭게 원소를 추가/삭제가 가능하다
Hash Table
: 데이터의 key 값을 해쉬 함수를 사용해 해쉬 값으로 변환후 데이터를 저장하거나 검색한다.
* 해쉬값이 겹쳐서 데이터를 어디에 넣을지 모르겠어요
=> 그럴땐, Separate Chaining 기법, Open Addressing 기법 이 있다구요
* Seperate Chaining
: 충돌이 발생할 경우 연결 리스트로 연결해서 데이터를 추가한다.
* Open Addressing
: 충돌이 발생할 경우 다른 빈 슬롯을 찾아 데이터를 저장합니다.
Tree
: 데이터 속 항목을 계층적으로 구조화하는 자료구조이다.
: 노드, 엣지를 가지고 있고 트리의 깊이를 레벨로 가지수를 디그리로 말한다
: 바이너리 트리, 밸런스 트리
바이너리 트리
: 자식 노드가 두개뿐
: 한쪽으로 치우칠 가능성이 있음
밸런스 트리
: 바이너리 트리의 한쪽으로 치우칠 가능성을 제거한 트리
: 한쪽으로 치우치지 않고 규칙을 세워 양쪽 노드가 잘 생성될 수 있도록 한다.
: B-TREE, B+ TREE
<정렬>
버블 소트
: 거품마냥 옆으로 가면서 값을 비교하며 정렬함(버블 버블)
설렉트 소트
: 최솟값을 찾아 맨앞의 요소와 위치를 바꾼다.
: 최악
인설트 소트
: 리스트의 요소를 하나씩 가져와 정렬된 앞부분 부터 비교해서 적절한 위치에 삽입
: 이것도 최악
퀵소트
:특정 값을 기준으로 리스트를 두개로 분할 후 정렬한뒤 다시 합치는 방식
: 최선 O(Nlogn)
: 최악 O(N^2)
<탐색>
순차 탐색
: 처음부터 모든 데이터를 탐색하는 방법
이진 탐색
: 정렬된 데이터에서 특정 값을 찾을떄 사용하는 탐색 방법
: 이미 **정렬된 데이터** 요게 중요
트리 탐색
: TREE를 이용해서 데이터를 탐색하는 방식
: 트리를 만드는데, O(N^2)이 들지만 트리 탐색은 O(logN)
DFS(Depth First Search)
: depth를 먼저 탐색하는 방식 child node 가 없으면 parent node로 다시 올라가 탐색한다.
BFS(Breadth First Search)
: 너비를 먼저 탐색하는 방식 다음 레벨 노드부터 순차적으로 탐색함
<컴퓨터 구조>
- CPU(Central Processing Unit) : 프로그램의의 명령어를 해석, 실행(ALU, 제어장치, 레지스터)
- Main Memory(First Memory) : 프로그램이나 데이터를 저장하는 공간 (RAM)
- Input Device : 명령을 입력하는 장치(키보드, 마우스)
- OutPut Device : 명령 처리 결과를 출력하는 장치(모니터, 스피커)
- Storage(Secondary Memory) : 반영구적 저장 장치(하드디스크, SSD, USB 플래시 드라이브)
- Bus : 컴퓨터 내부에 데이터와 명령어 전송 통로(주소 버스, 데이터 버스, 제어 버스)
- Board : CPU, Memory, Bus 등의 하드웨어 요소들이 담겨있는 회로 기판이다.
명령어 사이클
: CPU가 메모리로부터 1개의 명령어를 가져와 어떤 동작을 요구하는지 결정하는 이를 수행하는 연속적인 과정이다.
- Fetch : CPU입장에서 메인메모리로부터 다음 실행할 명령어(1 Word)를 인출한다.
- Decode : 명령어가 어떤 작업을 수행해야하는지를 결정한다
-> 오퍼랜드(Operand)와 연산자(Operator)를 구별
-> 해당 명령에 필요한 레지스터나 메모리 주소를 결정
- Execute : 명령어 실행
- Memory Access : 메모리에 접근해서 데이터를 읽거나 쓴다.
- Write Back : 계산된 결과를 레지스터에 저장한다.
명령어 파이프라이닝(Pipeling)
: 대표적 CPU
: 단계별 ( Fetch, Decode, Excute, Access, Write Back ) 연속 실행, 시간 동기화( Sync ), 한번에 여러 단계들을 실행한다.
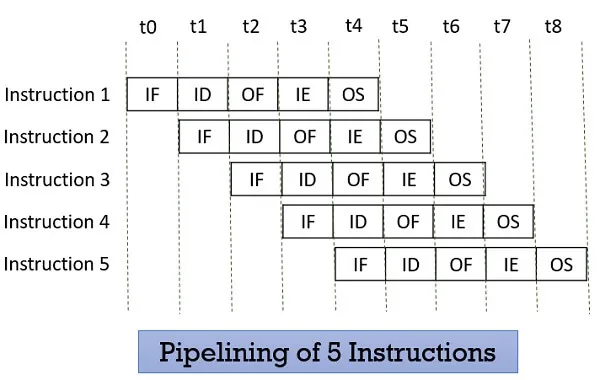
명령어 병렬처리(Parallelism)
: 대표적 GPU ( CPU도 사용하나 CPU 의 안정성때문에 GPU에서 많이 사용함 )
: 한번에 여러 작업을 수행하는 것, 시간 비동기( Async )
메모리 장치
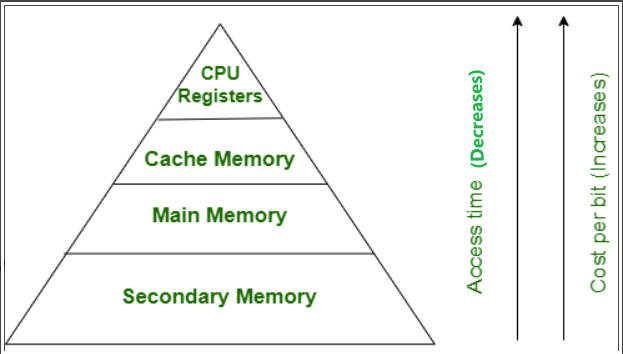
- Register : CPU 의 데이터나 명령어, 중간 결과값을 저장
- Cashe Memory : 실행 중인 프로그램의 사용할 명령어를 미리 가져와서 대기시켜 놓는 메모리
- Main Memory : 주기억장치
- Secondary Memory : 보조기억장치(SSD, HDD)
메모리 방식
- 반도체 방식
: ddram, ssd
- 자기장 방식
: 하드디스크
- 광학 방식
: cd_rom
* Nand Flash Memory
: 비휘발성이란, 메모리를 감싸고 있는 실리콘을 태워서 열산화성으로 데이터를 리셋하기 보단 실리콘을 태워 데이터를 저장한다 그렇기 때문에 요 메모리들은 자주 사용할수록 수명이 짧아진다.
'FastCampus UpStage AI > 컴퓨터구조' 카테고리의 다른 글
| 컴퓨터구조 - 명령어 (0) | 2024.10.14 |
|---|